Proteins are large molecules consisting of amino acids which our bodies and the cells in our bodies need to function properly.
Our body structures, functions, the regulation of the body’s cells, tissues and organs cannot exist without proteins.
Our muscles, skin, bones and many other parts of the body contain significant amounts of protein.
Protein accounts for 20% of total body Weight.
Why do we need Protein ?
Your hair, your nails, and the outer layers of your skin are made of the protein keratin. Keratin is a protein resistant to digestive enzymes. So if you bite your nails, you can’t digest them.
Bone has plenty of protein. the soft material inside the bone, also contains protein.
Red blood cells contain hemoglobin, a protein compound that carries oxygen throughout the body.
Finally, proteins play an important part in the creation of every new cell and every new individual.
Application or s/w that requires high computing capabilities and they are having large data sets may cause high I/O operations.
Due to these requirements they are overusing the super computing and cluster computing Infrastructures.
Protein structure Prediction is a computationally intensive task fundamental for different types research in the life sciences.
The prediction of the protein structure will help the medical scientists to develop new drugs.
This task requires the investigation of protein structure at so many number of states and also it is creating a large no of computing calculations for all of these states.
The computational Power required for this prediction can now be acquired online, without owning it.
Cloud computing grants the access to such capacity on pay per use basis.
A project that can analyze the use of cloud Technologies for protein structure prediction is JEEVA PORTAL.
It is an integrated web portal that enables the scientists to do the prediction task using cloud techniques.
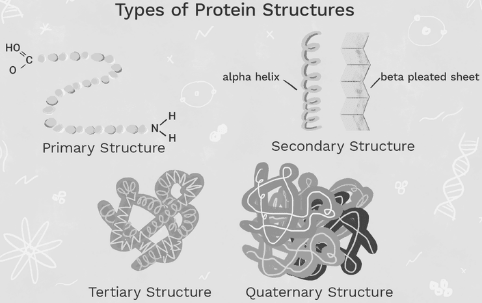
This prediction Task uses machine learning techniques for explaining the secondary structure of proteins.
These techniques will convert the problem in a manner so that they can be classified into 3 phases :initialization, classification and a final phase.
As It is already cleared By it’s name it the first phase of this prediction named “Initialization of protein structure prediction”.
The actual Prediction starts in the initialization phase .
In the second phase the execution is get completed concurrently.
This will reduce the computational time.
The prediction algorithm is then transformed into a Task graph and that is submitted to Aneka
Aneka is a platform and a framework for developing distributed applications on the Cloud. It harnesses the spare CPU cycles of a heterogeneous network of desktop PCs and servers or datacenters on demand.
Aneka provides developers with a rich set of APIs for transparently exploiting such resources and expressing the business logic of applications by using the preferred programming abstractions.
System administrators can leverage on a collection of tools to monitor and control the deployed infrastructure. This can be a public cloud available to anyone through the Internet, or a private cloud constituted by a set of nodes with restricted access.
Jeeva is a computational platform which simplifies the development of new prediction algorithms and improves the efficiency at the same time.
Jeeva web portal system consists of an interactive web interface and a Grid middleware.
With the interactive web interface, users can submit prediction requests for protein secondary structures, collect results, and manage the history of prediction data.
By means of the Grid middleware, researchers can not only deploy their prediction applications in a distributed environment easily, but also monitor and manage the execution in the distributed environment.
{kind=link}

{kind=link}
